Autonomous Quality Engineering for AI Agents
Your AI agents get better while you sleep.
Upload your agent traces. Spectral finds cross-agent failure patterns no human would catch, generates targeted fixes, and validates every change on data the optimizer never saw. Set a budget and walk away.
Free first scan · No credit card · Results in minutes
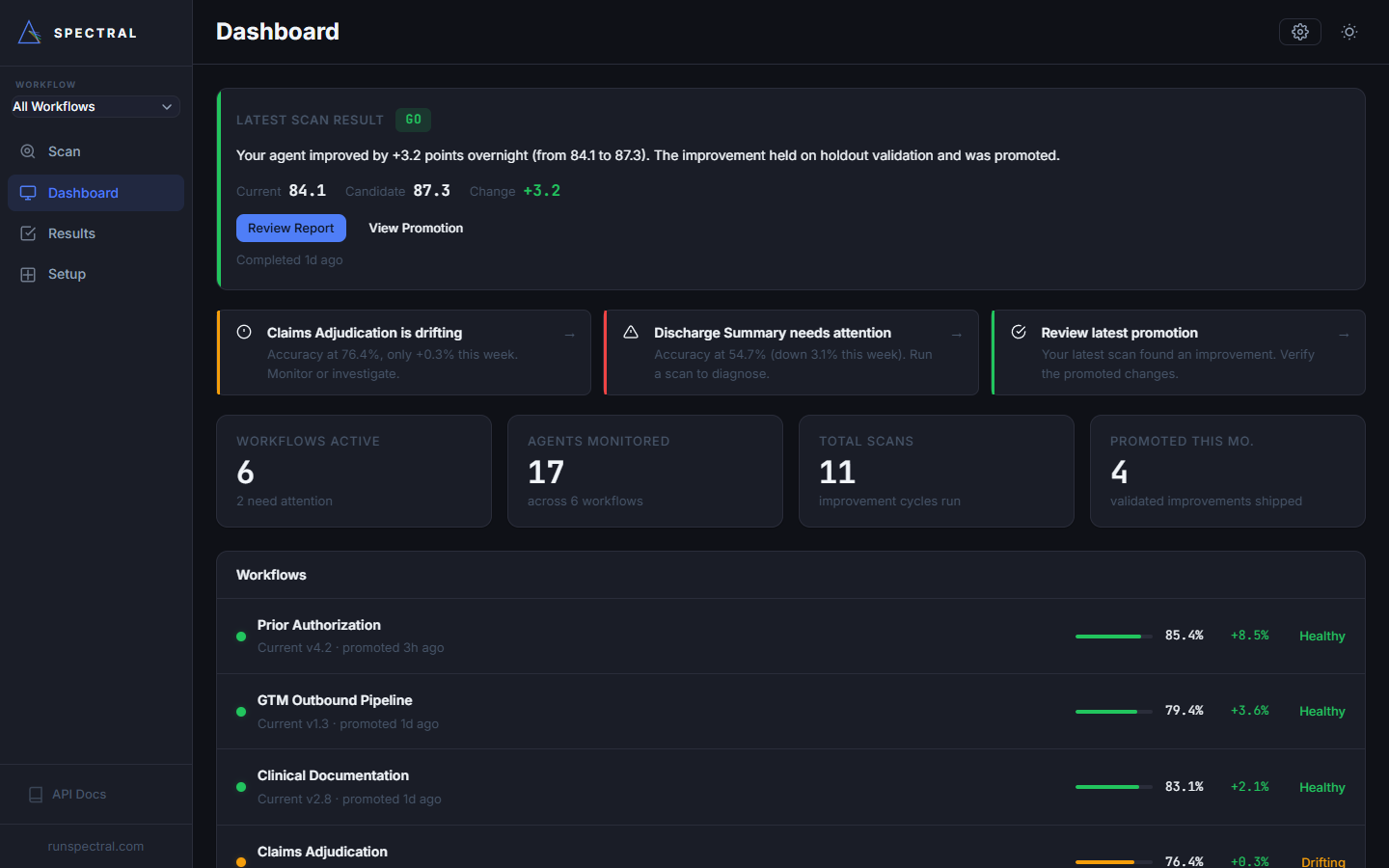
+19.9 points
on a healthcare prior auth pipeline
64.2 → 84.1 across 7 validated promotions. Fully autonomous.
14.5x cascade lift
found in under 10 seconds for $0
The agent that looks broken isn't the one that needs fixing. The failure tensor sees what trace logs can't.
0 regressions shipped
across 230+ autonomous scans
Every improvement validated on holdout data the optimizer never saw. Statistical rigor, not vibes.